chardetはPythonの文字エンコーディング検出ライブラリであり、公式Changelogでは、2006年の1.0が「Python 2 port of Mozilla’s universal charset detector」と説明されている。つまり、元々の出発点はMozilla系における実装を移植したものであり、その原作者はMark Pilgrim(以下Mark)である。
その後、プロジェクトは長く維持され、直近では2026年2月22日に6.0.0がリリースされている。6.0.0では依然として旧系統のchardetであり、7.0.0のリリース文書でも「previous versions were LGPL」と明記されている。そして、今回の問題となっているAIによる再実装版である7.0.0は2026年3月2日にリリースされ、その直後の3月4日には 7.0.1 も通常のバグ修正・改善のリリースとして出されている。つまり、7.x系は単発の実験ではなく、そのまま継続的なリリースとして開発されている。
問題の7.0.0について、公開されたChangelogとREADMEでは非常に率直に説明されている。そこでは7.0.0を「Ground-up, MIT-licensed rewrite of chardet. Same package name, same public API」と説明し、同じ名称、同じAPIのままMITライセンスへ切り替えたことを前面に出している。AIへの指示となるrewrite planにも、目的として「Build a ground-up, MIT-licensed, API-compatible replacement for chardet 6.x」と明記されている。現在のメンテナーであるDan Blanchard側(以下Dan)の公開文書から読み取れる基本線は、「同じpublic APIを持つ別実装を一から作ったのだからMITライセンスとして扱える」というものである。
著作権侵害の成立を検討することになるが、自分はソースコード解析の専門家ではないということは先に明らかにしておく。本件は、突き詰めるとComputer Associates v. Altai で確立されたAFCテストのような分析が必要なのだと思うが、そこまではコード比較の専門領域であり、自分が口を出すところではないだろう。したがって、ここでは公開されているrewrite planとその他のファイルの外形から見て、依拠性の事情がどこまで見えるか、そして類似性の推認がどこまで可能かを整理するに留める。
依拠性から見た評価
日本法では、著作権侵害成立の検討において最高裁判例に基づいた「依拠性」と「類似性」の判断が整理軸となっている。一方、米国法においてはもう少し段階が細かく検討され、“access, copying, substantial similarity, protectable expression”(依拠、事実上の複製、実質的類似性、保護されるべき表現)に分かれて語られるのだが、実務的にはやはり「元の著作物に接してそれを土台にしたのか?」「著作権保護される表現を取り入れたのか?」が核心的な侵害成立要件である。そして、米国法では17 U.S.C. §102(b)により、ソフトウェアの“idea, procedure, process, system, method of operation”(アイデア、手順、プロセス、システム、操作方法) そのものは保護対象外であり、保護されるのはあくまで表現のみである。Google v. Oracleなどの一連の訴訟においても、その制約がソフトウェアの著作権侵害を語る上で重要であることを改めて示している。
それらを踏まえ、公開されている再実装に使用したrewrite planの内容を見ていくと、依拠性については原作者であるMark側の主張がかなり筋が通っているように見える。Task 3のEncoding Registryにおいては、“Era assignments MUST match chardet 6.0.0’s chardet/metadata/charsets.py”(eraの割り当てはchardet 6.0.0の chardet/metadata/charsets.py と一致する必要があります) と書かれ、さらに “Fetch that file and use it as the authoritative reference”(このファイルを取得し、正式な参照として使用してください)、“Reference the chardet 6.0.0 charsets.py file … for the complete list of encodings and their era assignments”(エンコーディングとそのeraの割り当ての完全なリストについては、chardet 6.0.0のcharsets.pyファイルを参照してください) とまで記されている。つまり、少なくともregistry.py周辺については、旧版のcharsets.pyを明示的に見て、それを権威ある参照として一致させる指示が存在する。これはクリーンルーム実装の主張をかなり弱める材料となる。
さらにrewrite planには、テストデータ取得を行う手順も存在する。最終的な7.0.0のscripts/utils.pyでは、tests/data を https://github.com/chardet/test-data.git から shallow clone する仕組みになっており、その test-data リポジトリの README には、データは “pulled out into its own repo since licensing can be an issue”(ライセンスの問題が発生する可能性があるため、独自のリポジトリにまとめました) とされ、各testファイルはそれぞれのパブリッシャーの著作権だと記されている。ここから分かるのは、少なくとも再実装したメンテナー側自身がtest dataのライセンス問題を意識していたということである。
もっとも、依拠性が強く見えることと直ちに著作権侵害が成立することは別問題である。米国法における著作権侵害の判断は日本法より厳密であり、何が保護される表現なのかを細かく見る。Feist v. Ruralでは、事実の編集物はそれ自体当然に保護されるわけではなく、保護されるとしても事実そのものではなく選択、体系化、配列の創作性のある部分だけだと述べた。さらに、Computer Associates v. Altaiは、ソフトウェアの非文言侵害では抽象化・濾過・比較テスト(AFCテスト)によって、保護されない要素を先に落としてから比べるとした。つまり、米国法では単にプログラムの論理構造や機能が似ているだけでは直ちに著作権侵害とはならず、その類似性が保護される創作表現に該当するのかを厳しく精査されるのである。
そもそも、charsets.pyはその多くがメタデータの表であり、これは事実に近い性質であって保護される表現ではないという主張も成り立つが、表の選択・分類・割当に人間の創造性が認められれば、それを複製し、registry.pyに実質的に取り入れれば類似性の判断が成り立つ余地がある。ここで重要なのは、エンコーディング名の集合、eraの概念、対応するPython codec名、言語とのひも付けのかなりの部分は、機能、規格、あるいは事実に近い領域でもあるということである。仮にregistry.pyが旧charsets.pyを参照して作られていたとしても、それだけで再実装した7.0.0全体が旧chardetの複製または翻案とまでは言い切れないだろう。少なくとも米国法では、似ているだけでなく、「その似ている部分が保護される表現なのか」がさらに問われるからである。Dan側から見れば、rewrite plan に旧版参照があるとしても、それは機能互換やデータ整合のための参照に過ぎず、保護される表現の取り込みを意味しない、という反論が中核になる。
また、仮に著作権侵害が全面的に否定されたとしても、契約論が完全に消えるわけではないのでその観点での争点もあり得る。LGPL 2.1は改変・頒布による受諾を前提としており、米国ではオープンソースライセンスの条件違反が契約または著作権侵害として成立するかが長年に渡って争われてきた。Artifex v. HancomではGPLをめぐって契約違反と著作権侵害の双方が主張され、SFC v. VizioでもGPL/LGPLをめぐる契約的争点が現在も継続されている。もっとも、本件ではやはり中心は著作権侵害であり、契約論だけで全部を片付けられる事案ではないが、AIによる再実装が激増すると考えられる以上、著作権侵害だけで片付けない姿勢が今後必要になることに留意する必要があるだろう。
7.0.0は公開文書上、自ら”Same package name, same public API”(同じパッケージ名、同じ公開API)と主張している。しかも、Mark側が異議をイシューで述べた後も、7.0.1が通常のバグ修正・改善リリースとして開発が継続されている。現時点では少なくともMark側の主張が受け入れられず、そのまま新系統がプロジェクトの後継を名乗って走っている状態である。
一方で、データセットという形で複数の作品を集約している場合でも、それ自体は各作品の単なる集合体であって翻案ではない点にも注意が必要である。CCライセンスでは「作品をコレクションに含めること自体は翻案に当たらない」旨が明示されており、そのためたとえCC BY-SAのような継承条件付きの作品をデータセットに収録したとしても、データセット全体が自動的にCC BY-SAライセンスが適用になるわけではない。ただし、頒布に際してトリミング、色補正、ノイズ除去、キャプション付与や翻訳等の前処理を施す場合、その前処理が個々の作品の改変(翻案)に当たり得るため、NDやSAの適用関係が別途問題となり得る点に留意が必要である。継承(SA)条件が問題となるのは、あくまで元作品を翻案(改変)して共有した場合であって、単に元作品を無改変でまとめただけのデータセット(集合著作物)には直ちに適用されるわけではない。ただし、データセット内の個々の作品には引き続き元のCCライセンス(および著作権)が及んでいるため、利用者に対してその点を明示すること、例えば「本データセットにはCC BY 4.0ライセンスのコンテンツをX点含む」等のような表記をすることが望ましい。
先日、NVIDIAがリリースしたオープンウェイトのAIモデル「Nemotron 3」に関し、それをオープンソースだとして誤って報道するメディアが散見される。それらによってNemotron 3のライセンスであるNVIDIA Open Model License Agreement(2025年10月24日版:以下、NVIDIAライセンス)の利用リスクを無視する動きが懸念されるため、ここでそのオープンソース性と特に大企業におけるモデル利用時のライセンス上のリスクについて整理する。
NVIDIAライセンスは、モデルの学習済みウェイト等に適用される独自ライセンスであり、Open Source Initiative(OSI)が定める「オープンソースの定義」(Open Source Definition:OSD)に基づいてその定義に適合するかを検討する必要がある。一見すると、確かにNVIDIAライセンスでは、モデルの商用利用や派生モデルの作成や頒布に対して一定の自由を許諾しており、また、モデルの出力に対してはNVIDIAライセンスではNVIDIAが権利を主張しないことが明記されている。OSDはソフトウェアの利用・改変・再頒布に関する要件を定義するものであり、モデル出力の帰属を直接規律する条項はない。もっとも一般に、成果物に対する権利関係は成果物自体の性質や第三者権利の有無に依存し、ライセンス条件が当然に出力へ波及すると整理されるとは限らないが、NVIDIAライセンスでは「NVIDIA claims no ownership rights in outputs」と明記しており、この点は利用者に有利な条項であり、またこのような出力の自由を併せてNVIDIAライセンスはオープンソース的な特徴をある程度持っているとは言えるだろう。
NVIDIAライセンス第3条は、モデルや派生モデルを頒布・提供する際の義務も定めているが、その中で特に注目すべきはNVIDIAへのクレジット表示義務である。ライセンスのコピー添付やNoticeファイルでの所定の表示(「NVIDIA Open Model Licenseの下でライセンスされています」等)に加え、対象がNVIDIA Cosmosモデルである場合には製品やサービスのWebサイト、UI、ドキュメント等に「Built on NVIDIA Cosmos」の文言を表示することが求められている。
米国著作権法においては、基本的に人間が創作したもののみを保護するという立場を明確に打ち出している。AIが自律生成した画像の著作権登録を巡る訴訟として近年話題となったThaler v. Perlmutterでも、D.C.巡回区控訴裁判所は一貫して「人間の著作物性は著作権の根幹を成す要件である」と判示し、純粋にAIだけで作られた作品には著作権を認めないとの結論を下している。この点は、日本法では明文化されていないものの実質的には同様に考えられている部分ではあるが、米国では判例と条文解釈の運用上により明確に人間の著作者性が要求されると言えるだろう。
さらに、Computer Associates v. Altai(第2巡回区控訴裁判所)において有名な抽象化・濾過・比較テスト(AFCテスト)が示され、プログラムの非文字的要素(構造やUIなど)が著作権保護されるかを判断する枠組みが確立した。このテストは、まずプログラムを抽象度の高い構造まで分解し、次にその中から効率上の必要に迫られた要素、外部仕様から要求される要素、パブリックドメイン領域から取得された要素を順次取り除き、そうして最後に残った部分が創作的表現として保護され得る部分であり、その部分について他の作品との実質的類似性を比較検討するという手法である。要するに、機能的あるいは規範的な要素をフィルタリングして純粋な表現部分を抽出するという考え方であり、表現とアイデアの切り分けを厳密に行う点が特徴である。米国法はこの点について日本法よりも制度的および判例上明文化されている分、判断手法が洗練されているとも言える。
2021年にGitHub Copilotが登場した当時、そのモデルの学習データにGitHub上のあらゆる公開されたオープンソースのソースコードが含まれていることが大きな注目を集め、ライセンスに関する議論が活発にされた。ほとんどのライセンスで規定される帰属表示などの条件の問題もあるが、特にGNU GPL(GNU General Public License)のようなコピーレフトライセンスの条件がモデルにも伝播し、モデル全体を同じライセンスで公開する必要があるという言説が多く飛び交った。GPLの伝播性自体は現代の多くのソフトウェアエンジニアが自然に受け入れているものであり、エンジニアの素朴な感覚としては何らかの形でGPLコードが含まれるのであれば当然コピーレフトが適用され、ライセンスが伝播すると考えるのはごく自然な成り行きである。
まず、「AIモデルへのGPL伝播理論」とは何か?を整理しておく。これは、AIモデルがGPLコードを学習データとして取り込んだ場合に、そのモデル自体がGPLコードの二次的著作物(派生物)に当たるため、モデルを頒布する際にはGPLにおけるソースコード公開義務等のコピーレフトの条件が適用される、とする考え方である。すなわち、モデルの出力がGPLコードと類似しているか否かという問題ではなく、「モデルそのものがGPLコードを含む派生物であるからモデルにもGPLが及ぶ」という理論である。2021年前後にはこの理論を支持する声が多く聞かれたが、前述の通り現在では議論の主流ではなくなっている。しかし、この理論が完全に否定されたとは言い切れない根拠として、現在進行中の二つの主要な訴訟が挙げられる。それが、米国で提起されたDoe v. GitHub(Copilot集団訴訟, Doe 1 et al v. GitHub, Inc.)とドイツで提起されたGEMA v. OpenAIである。以下、それぞれの訴訟の経緯と現状を説明する。
Doe v. GitHub(Copilot集団訴訟):残り続けるオープンソースライセンス違反クレーム
このGEMA判決が示す特筆すべき理論は、著作権法上の複製概念をモデル内部にまで拡張することである。つまり、学習データとして使用した著作物がモデル内に残存し、それを簡単な操作で再現できるのであれば、モデルは既にその著作物の複製物を含んでいるということになる。この理論は、「モデルが学習元著作物を含有している」とみなす点で画期的であり、実際Osborne Clarkeによる解説でも「英高等法院のGetty v. Stability AI事件の判断とは対照的に、ミュンヘン地裁はAIモデルが学習素材のコピーを含んでいる可能性を明示的に認めた」と評価されている。この見解に立てば、モデルは単なる分析の結果ではなく、場合によっては学習データそのものの集合体とも評価し得ることになる。
まず、著作権法上ではAIモデルを「学習元著作物の二次的著作物」や「複製物」と見なすことには無理がある。多くの場合、モデルの内部には特定の著作物の表現が人間に認識可能な形では格納されていない。モデルはテキストやコードを重みパラメータに変換した統計的な抽象を保持しているに過ぎず、それ自体は人間にとって何ら創作的表現ではない。著作権法上の「二次的著作物」とは、原著作物の表現上の本質的特徴を直接感得できる形で取り入れた創作物を指すが、モデルの重みからは元コードの創作性を直接感得することはできない。言い換えれば、モデルは元コードを内包していると評価できるほどには直接的に作品としての性質を示さないのである。例えば、英国高等法院はGetty v. Stability AI事件の判断で「Stable Diffusionのモデルそのものは学習画像の侵害的複製物ではない」と述べており、モデルを著作物の複製と見なすことに否定的な見解を示した。このように、モデル自体を著作物の集積ないし編集著作物とみなすことには国際的にも慎重な立場が多い。
まず、OSIは2024年に「オープンソースAIの定義」(OSAID:Open Source AI Definition)を策定し、AIシステムがオープンソースと呼べるための要件を定めた。この定義では、AIシステムに対してもソフトウェアと同様の4つの自由(利用・研究・改変・再頒布)を保障すべきとしており、その実現のために必要な要素として「改変に必要な形式」に関する要件も定めており、そこで以下の3要素を開示することが求められる。
Software Freedom Conservancy(SFC)は当然のようにこの問題に強い関心を寄せているがやはり慎重な所もある。SFCは2022年にGitHubに対する抗議キャンペーン「Give Up GitHub」を開始し、Copilotのやり方はオープンソースの理念に反すると非難しており、Copilot集団訴訟にも関与している。ただし、SFCのブログ記事では、この訴訟について「オープンソースコミュニティの原則から外れた解釈が持ち込まれるリスク」に懸念を示し、原告側にもコミュニティ主導のGPLエンフォースメント原則を遵守するよう呼びかけている。SFCは、Copilotの行為が「前代未聞のライセンス違反」であるとも述べており、GPL伝播理論に対して全面否定ではないものの法廷闘争の結果次第ではコミュニティにとって望ましくない判例ができることを恐れているとも取れるだろう。SFCはGPL伝播を追及する側面と司法に委ねるリスクとの間で慎重にバランスを取っていると言えるかもしれない。
以上、AIモデルへのGPL伝播理論の現在地を見てきたが、結論として本理論は「かつてほど喧伝されなくなったが、完全に消え去ったわけではない」という中途半端な位置にある。Copilot集団訴訟やGEMA v. OpenAI訴訟といった訴訟の中で、学習データのライセンス違反やモデル内の複製という論点が精査され始めた結果、かえって侵害認定のハードルは下がりつつあるようにも見える。実際、ミュンヘン地裁の判断はモデル記憶を複製とみなし、Copilot訴訟ではオープンソースライセンス違反の主張が生き残っている。
今後であるが、OpenAIは間違いなく控訴すると考えられるが、やはりAIモデルを「法的な複製」とみなす論は崩されやすいように感じている。英国のGetty v. Stability AI訴訟でまさにここをOpenAIの言う「確率的合成」とみなしたばかりでもあり、国際的な判例との齟齬を突きやすい。しかしながら、地裁判決とは言え、包括的なライセンスモデルを推進していた権利者団体側がここまで綺麗に完勝した事実は大きそうだ。Web上のデータは無料の訓練素材という考え方は少なくともEUでは厳しい傾向になるのではないかと思う。
オープンソースのプロジェクトで採用されているCoC (Code of Conduct, 行動規範)を巡る議論が、一つの転換点を迎えているかもしれない。2025年9月、Rubyのエコシステムを支えるRubyGemsのガバナンスを巡る騒動が勃発し、コミュニティに大きな波紋を広げている最中であるが、これと直接的には関係がないもののこの混乱をきっかけにRuby on Railsの作者であるDavid Heinemeier Hansson(DHH)とオープンソースの元伝道師であるEric S. Raymond(ESR)という二人の有名人が、現代的なCoC、特に「Contributor Covenant」に対して痛烈な批判をX上で展開するという出来事があった。
Rubyの日本国外のコミュニティではMINASWAN(Matz is nice and so we are nice.:Matzは優しい、だから私たちも優しくあろう)という精神が掲げられることがあるが、これは開発者とコミュニティの相互の幸福のために加者同士が思いやりと尊厳を持って接することを求めているのだろう。細かい条項や政治的理念をわざわざ明文化しなくとも、運用が容易でありながら、他者を尊重する文化の形成には参加者が共有できる理念を掲げるだけで十分に機能するのである。
米国においてオープンソース・ライセンスが契約ではなく「著作権の一方的な許諾」であると長らく見做され、Jacobsen v. Katzerの訴訟でその効力が法的にも認められるようになった流れは前回の記事で解説したが、一方でこの訴訟の判決はオープンソース・ライセンスが法的に強制力のある契約として認知されるまでの道のりの一歩でもあった。
今日のオープンソース・コンプライアンスを語る上でこのJacobsen v. Katzer判決の意義は計り知れないものがある。第一に、オープンソース・ライセンスへの違反が著作権侵害となり得ることを明確に確立し、ライセンスに法的な根拠を与えたことは大きい。これにより、オープンソース開発者は違反者に対して差止請求という強力な救済手段を行使できるようになったわけであり、これは同時に公開したソースコードの利用方法に法的な統制を及ぼしたいと考えるコピーレフト型ライセンスの根幹を支える法的基盤となったとも言える。
Jacobsen判決によってオープンソースのライセンス違反が著作権侵害として確立された一方、あらゆるライセンス条項への違反が即座に著作権侵害となるわけではないという重要な境界線を画定したのが、2011年のMDY Industries, LLC v. Blizzard Entertainment, Inc.事件における第九巡回区控訴裁判所の判決である。
この訴訟は、オンラインゲーム「World of Warcraft」を巡るものであり、被告のMDYはゲームを自動プレイするボットを販売していたのだが、原告のBlizzardはWoW利用規約においてボットの使用を明確に禁止していた。そこでBlizzardは、ボットの使用が利用規約違反であり、利用規約がソフトウェア利用許諾契約の一部であるために許諾範囲を逸脱した著作権侵害に当たると主張したのである。
この判決により、ライセンサーは違反された条項の性質に応じ、著作権侵害に基づく差止請求と契約違反に基づく損害賠償請求を使い分けるか、若しくは併用するという二段構えの戦略を取る法的基盤が整った。この流れが、次のArtifex v. Hancom事件における判断へ直接つながっていくことになる。
Artifex v. Hancom (2017年):ライセンスの契約性と金銭的救済手法を裁判所が明確に許容
Jacobsen判決が「著作権侵害」となり得る道を開き、MDY判決が「著作権侵害」と「契約違反」を選別した後、オープンソース・ライセンスの契約としての側面を決定的に確立したのは2017年のArtifex Software, Inc. v. Hancom, Inc.訴訟である。先に書いてしまうと、ここでの裁判所の命令は、GNU General Public License(GPL)が法的に強制力のある「契約」として成立することを明確に認め、さらにその違反に対する金銭的な損害賠償の算定方法にまで踏み込んだ点で画期的であり、オープンソース・コンプライアンスにおける今日の実務で中核的参照点になっている。
これまでの三つの訴訟が、ライセンスの「執行可能性(Jacobsen)」、その「範囲(MDY)」、そして「契約性と金銭的救済(Artifex)」を確立してきたのに対し、現在も進行中のSoftware Freedom Conservancy, Inc. v. Vizio, Inc.訴訟は、ライセンスを執行できる「主体」は誰かという我々のオープンソース・コミュニティとして未知の領域への問いを投げかけている。
SFC v. Vizio訴訟がどのような帰結を迎えるかはまだ判然としないが、企業がオープンソースとどう向き合うべきか、その戦略の根本的な見直しを迫るものとなる可能性が高いだろう。
2. ライセンス違反リスクへの影響
Jacobsen判決からSFC v. Vizio訴訟に至る一連の訴訟における法解釈は、オープンソース・ライセンスが著作権法に基づく「条件付きの許諾」と契約法に基づく「双務的合意」という二つの顔を持つことを確立したと言える。この二重の法的構造は、ライセンス違反がもたらすリスクを質と量の両面で劇的に増大させた。
デュアルライセンス戦略は、オープンソース開発ベンダーにとって持続可能なビジネスモデルを構築するための一般的な手法であるが、Artifex v. Hancom訴訟の地裁命令以降、この戦略はライセンス違反者に対して強力な経済的制裁を科すための法的ツールとしての側面も持つようになった。何故なら、この訴訟の地裁命令が、GPLのようなコピーレフト型ライセンスの違反に対する損害賠償額を対応する商用ライセンスの料金に基づいて算定できることを示したからである。
この理論は、米国だけに特有のローカルな考え方ではない。2024年2月にフランスのパリ控訴裁判所が下したEntr’ouvert v. Orange事件の判決は、このリスクが国境を越えて普遍的なものであることを明確に示したと言える。原告のEntr’ouvertはLassoという認証ライブラリをGPLと商用ライセンスのデュアルライセンスで提供していたが、大手通信事業者であるOrangeはポータルサイト開発においてLassoを利用したがGPLの義務を遵守せず、商用ライセンスも購入しなかった。これに対し、パリ控訴裁判所はOrangeに対して著作権侵害とライセンス違反を認定し、損害賠償金として500,000ユーロ、精神的損害として150,000ユーロ、不当利得の吐出として150,000ユーロ、費用等として60,000ユーロの支払いを命じたのである。
これまでの日本国内でのライセンス違反に関する訴訟リスク議論というものは、漠然と日本法による日本国内での訴訟を念頭に置かれることが多かったように思う。しかし、Source Availableライセンス適用のツールを含めて、現代の重要なオープンソース・ソフトウェアの権利者は米国の企業か組織であることがほとんどであり、Artifex v. Hancomでの判示が確立した米国での契約論ベースで考えれば、それらの米国企業が米国の所在地の州の裁判所にて契約法を根拠として日本企業に対して訴訟を提起することが十分にあり得る。いや、あり得るではなく、現実にArtifex v. Hancomで被告となったHancomは韓国の企業であり、米国内での販売・頒布・サポート等の行為があったことで地裁の個別管轄が通ったのである。GPL違反=契約違反として捉えることによって「米国著作権法は原則として域外行為に及ばない」という域外行為に対する壁が乗り越えやすくなっていると言えるだろう。
オープンソース・コンプライアンスにおけるリスクの最終地点は、訴訟主体が不特定多数のエンドユーザーにまで拡大することではなかろうか? Artifex v. Hancom判示が確立した「ライセンス=契約」という法的地位と、SFC v. Vizio訴訟で現在進行形で争われている「エンドユーザー=第三者受益者」という理論が組み合わさった場合、米国の権利者のオープンソースのソフトウェアを多く利用し、米国市場においても製品やサービスの提供を行う多くの日本企業にとって、これまでにない規模と性質の訴訟リスクが出現することになる。
例えば、ある日本の自動車メーカーの車載インフォテインメント・システムにあるGPLと商用ライセンスのデュアルで提供されるツールを搭載した新型車を米国で販売すると仮定する。Artifex判示の論理によれば、このメーカーは自動車を米国の消費者に販売(頒布)した時点で、ツールの開発ベンダーとの間でGPLという契約を締結したとみなされる。契約の条件には、要求に応じてシステムの完全な対応ソースコードを提供する義務が含まれるからである。そして、ある消費者がこの新型車を購入し、車載システムを独自にカスタマイズしたいと考え、メーカーにGPLに基づいてソースコードの提供を要求する。しかし、何らかの理由で要求は無視されるか、不完全なコードしか提供されなかったとしたらどうなるか? SFC v. Vizio訴訟でSFCが勝訴した場合、この消費者個人はGPL契約の「第三者受益者」として、ソースコードの提供を求めて日本の自動車メーカーを米国の裁判所に提訴する法的権利(当事者適格)を持つことになるのである。
このように、Artifex判示とSFC v. Vizio訴訟の流れが合流する地点には、多くのオープンソースの利用者側となる日本企業にとっての非常に厳しい訴訟環境が形成されつつある。オープンソースの利用においては、特に米国法における法的リスクを管理する高度なガバナンスを要求する状況となっているのである。
Jacobsen v. Katzerは、オープンソース・ライセンスの帰属表示等の条件を著作権上の可罰的条件として認め、その違反は著作権侵害になり得るとした。そして、Artifex v. HancomはGPLを契約としても執行可能とし、SFC v. Vizioによって著作権者本人でない主体が第三者受益者としてソース開示等を迫れる可能性が見えてきている。このような状況は我々の自由を追求するコミュニティの一部が求め続けていたものであり、ライセンスを遵守しないと法的リスクがあるという強制性が働くことはオープンソースのエコシステム維持には一定の福音であるのかもしれない。
さらにもう一点、本稿ではあくまで米国におけるオープンソース・ライセンスの契約性の確立とその影響について論じてきたのであるが、Artifex v. HancomはGPLを契約としても執行可能とした理論は多くの日本企業へのリスクとなっていることは確かであるものの、実はあるオープンソース以外の製品利用のリスクがGPL系よりも高まっていると考えている。SSPL(Server Side Public License)やBUSL(Business Source License)を適用するSource Availableと呼ばれるライセンスを採用する製品群を採用するリスクである。これらのライセンスを適用する製品は総じて商用ライセンスとのデュアル戦略であり、オープンソース企業とは異なりコミュニティの評判を気にする必要もない。業績が少し傾くだけで、訴訟戦略に打って出る動機が強くあるのである。
Jacobsen v. Katzerは、ライセンス違反が著作権侵害を構成し得ることを確立し、オープンソース・ライセンスに差止請求という「法的な牙」を与えた最初のマイルストーンであった。MDY v. Blizzardは、著作権侵害と契約違反の境界を画定し、ライセンスの二重構造をより的確なものにした。Artifex v. Hancomは、GPLが強制力のある契約であることを認め、違反に対する損害賠償額を商用ライセンス料に基づいて算定できるという金銭的リスクの枠組みを構築した。そして、現在進行中の SFC v. Vizioは、ライセンスを執行する権利がエンドユーザーという「第三者受益者」にまで拡大する可能性を示唆し、コンプライアンス・リスクの主体を根本から変えようとしている。
Grok 2ライセンスの第2条では、「許可された利用」を定めており、モデルの利用を非商用・研究目的と商用の場合に分類している。そして、商用利用にはxAIのAcceptable Use Policy(AUP) を順守する場合のみ利用を認めると明記されており、これは利用目的に応じて条件を課していると言える。また、2条(b)では、公開されたモデルや派生物、生成物を用いて他の基盤モデルや汎用AIを学習・作成・改良することを禁止している。さらに、第3条では「Powered by xAI」という表示を目立つ形で義務付ける条件もある。
こうした条項は、OSIの「オープンソースの定義」(OSD)が求める基本原則に抵触する。OSDは、派生物を自由に作成・頒布できること(第3条)や商用利用を含むあらゆる分野への差別的な利用制限を設けないこと(第6条)を求めており、また、昨年にOSIが発表した「オープンソースAIの定義」(Open Source AI Definition 1.0: OSAID)では、AIシステムを自由に「使用・研究・改変・共有」する権利をあらゆる目的に対して保障することが必要とされている。xAIのライセンスはAUP順守義務や他モデルへの学習利用の禁止といった用途制限を課しているためこれらの要件を満たさず、よってオープンソースと称することはできない。
不明確な「商用閾値」とライセンスの矛盾
ここまではMeta Llamaと然程変わらないわけだが、Grok 2 Community Licenseには実は他にも不可解な点がある。
このようなタイミングで、xAIがLlamaライセンスに似た独自条項を備えたGrok 2 Community Licenseでモデル公開を行ったことには疑問が残る。Llamaライセンスほどの複雑な問題は生じないものの、商用閾値やAUP遵守など独自の制約は利用者にとって扱いづらさが増している側面もあるだろう。xAIが最新モデルの普及を目指すなら、コミュニティが受け入れやすい形にライセンスを見直す必要がある。
おわりに
まとめると、xAI が公表したGrok 2 Community License Agreementは、モデルの使い道や再利用に広範な制限を課しており、「オープンソースの定義」が求める自由には適合しない。とりわけ、AUP準拠義務や他モデルへの学習禁止は「用途に関する差別」を禁じたOSD第6条やOSAIDの「どのような目的でも使用可能」という条件に反している。また、定義されていない商用閾値や出力利用の矛盾もあり、ライセンス文面の品質にも大きな疑問が残る。
この「連邦著作権法の抜け穴」と「ハッカー文化」から生まれた一方的許諾の慣習は、やがて法廷の場でその正当性が問われ、判例によって思想が強力に補強されていった。まず、Effects v. Cohen(1990年)のような判例を通じて、書面がなくても当事者の行動からライセンスの成立を認める「黙示のライセンス」という考え方が確立されたことが大きい。この判例は、行動が許可を生むという黙示のライセンスの基本原則を確立したリーディングケースであるが、これによって形式的な契約書がなくとも実態に即してライセンスの存在を認める道が大きく開かれ、「一方的許諾」の法的な実在性が裏付けられたと考えられている。
そして、決定的であったのが、Jacobsen v. Katzer(2008年) というオープンソースコンプライアンスの領域でのランドマーク的な判決であろう。 この裁判で連邦巡回区控訴裁判所は、オープンソースのライセンス違反は単なる契約違反ではなく、著作権侵害そのものであるとの判断を示した。ライセンスに書かれた義務は、ライセンスが有効であるための前提となる条件であり、それに反することは許可の範囲を超えた無断利用にあたると結論付けたのである。この判決により、「一方的許諾」の宣言は、連邦著作権法でその履行を強制できることが証明された。
Subject to your compliance with this agreement, permission is hereby granted, free of charge, to deal in the Model Materials without restriction, including under all copyright, patent, database, and trade secret rights included or embodied therein. あなたが本契約を遵守することを条件として、モデルマテリアルに含まれる、またはその中に具現化された全ての著作権、特許権、データベース権、及び営業秘密の権利を含め、いかなる制限もなくモデルマテリアルを無償で取り扱う権限をここに許諾します。
If you file, maintain, or voluntarily participate in a lawsuit against any person or entity asserting that the Model Materials directly or indirectly infringe any patent, then all rights and grants made to you hereunder are terminated, unless that lawsuit was in response to a corresponding lawsuit first brought against you. モデルマテリアルが直接的または間接的に特許を侵害していると主張する個人または団体に対し、あなたが訴訟を提起、継続、または自発的に訴訟に参加した場合、当該訴訟があなたに対して最初に提起された関連訴訟に対するものでない限り、本契約に基づきあなたに付与された全ての権利および許諾は終了します。
Linux FoundationがOpenMDWライセンスをいまだにOSIのオープンソース承認プロセスに申請していない理由はよく分からないが、私はOpenMDWライセンスをよく考えられた優れたライセンスであると現時点で認識している。オープンウォッシュを助長するという理由はオープンソースへの承認を否定する理由にはならないだろう。むしろ、これはOSIを中心としたオープンソースのライセンスコミュニティに対してAI関連のライセンスに関する課題を明確にしてくれたと考えている。
As used in this agreement, “Model Materials” means the materials provided to you under this agreement, consisting of: (1) one or more machine learning models (including architecture and parameters); and (2) all related artifacts (including associated data, documentation and software) that are provided to you hereunder.
Subject to your compliance with this agreement, permission is hereby granted, free of charge, to deal in the Model Materials without restriction, including under all copyright, patent, database, and trade secret rights included or embodied therein.
If you distribute any portion of the Model Materials, you shall retain in your distribution (1) a copy of this agreement, and (2) all copyright notices and other notices of origin included in the Model Materials that are applicable to your distribution.
If you file, maintain, or voluntarily participate in a lawsuit against any person or entity asserting that the Model Materials directly or indirectly infringe any patent, then all rights and grants made to you hereunder are terminated, unless that lawsuit was in response to a corresponding lawsuit first brought against you.
This agreement does not impose any restrictions or obligations with respect to any use, modification, or sharing of any outputs generated by using the Model Materials.
THE MODEL MATERIALS ARE PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE, TITLE, NONINFRINGEMENT, ACCURACY, OR THE ABSENCE OF LATENT OR OTHER DEFECTS OR ERRORS, WHETHER OR NOT DISCOVERABLE, ALL TO THE GREATEST EXTENT PERMISSIBLE UNDER APPLICABLE LAW.
YOU ARE SOLELY RESPONSIBLE FOR (1) CLEARING RIGHTS OF OTHER PERSONS THAT MAY APPLY TO THE MODEL MATERIALS OR ANY USE THEREOF, INCLUDING WITHOUT LIMITATION ANY PERSON’S COPYRIGHTS OR OTHER RIGHTS INCLUDED OR EMBODIED IN THE MODEL MATERIALS; (2) OBTAINING ANY NECESSARY CONSENTS, PERMISSIONS OR OTHER RIGHTS REQUIRED FOR ANY USE OF THE MODEL MATERIALS; OR (3) PERFORMING ANY DUE DILIGENCE OR UNDERTAKING ANY OTHER INVESTIGATIONS INTO THE MODEL MATERIALS OR ANYTHING INCORPORATED OR EMBODIED THEREIN.
IN NO EVENT SHALL THE PROVIDERS OF THE MODEL MATERIALS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE MODEL MATERIALS, THE USE THEREOF OR OTHER DEALINGS THEREIN.
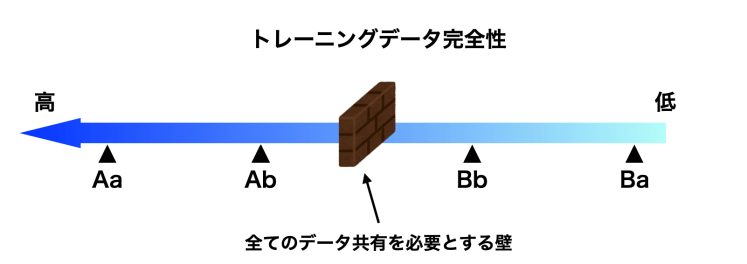
昨年10月、Open Source Initiative(OSI)は「オープンソースAIの定義」(OSAID: Open Source AI Definition)を公表しており、それに従えばオープンソースAIであるためには完全なトレーニングデータが存在することは推奨されるものの必須とする要素ではなく、基本的にはトレーニングデータの詳細な情報があれば済むという定義となっている。現状ではこのOSIの方針は妥当な考え方であるとの見方が強いと考えているが、その一方で「完全なトレーニングデータの公開を必要とする論」及び「データの公開は全く必要としない論」の相反する二つの考え方が根強くある。本稿ではその対立の背景を踏まえつつ、OSIの考え方が導き出されるまでの解釈を説明する。
この四つの主張はデータの完全性という一つの直線の尺度の上にプロットして並べていくと、データの完全性が高い順に Aa – Ab – Bb – Ba という並びになるのだろう。オープンソースであるかどうかということはYesかNoの二値で表現するしかない問題であり、よってこの尺度の上のどこかにオープンソースとして認める明確なラインを引くことになる。
意見を4つに分類することで Aa – Ab – Bb – Baの尺度のどこかにオープンソースAIであると認めるラインを引かねばならないということだけははっきりしているが、どこにそのラインを引くかはもっと原理原則に立ち返って詳細に検討しなければならない。
2. AI領域におけるOSD 2条「ソースコード」の探究
トレーニングデータの完全性をどこまで求めるかを詳細に検討するためには、やはり「オープンソースの定義」(OSD: Open Source Definition)という根本的な原則に基づいて考える必要がある。現在のOSDのバージョンは2004年にリリースされた1.9であり、20年以上変更がない。オープンソースであるための条件として完全に安定化していると言えるだろう。そして、このOSDをAIシステムに対して適用する場合、問題となるのは下記の第2条「ソースコード」である。
OSD Section 2. Source Code:
The program must include source code, and must allow distribution in source code as well as compiled form. Where some form of a product is not distributed with source code, there must be a well-publicized means of obtaining the source code for no more than a reasonable reproduction cost, preferably downloading via the Internet without charge. The source code must be the preferred form in which a programmer would modify the program. Deliberately obfuscated source code is not allowed. Intermediate forms such as the output of a preprocessor or translator are not allowed. (オープンソースであるプログラムはソースコードを含んでいなければならず、コンパイル済形式と同様にソースコードでの頒布も許可されていなければなりません。何らかの事情でソースコードと共に頒布しない場合には、ソースコードを複製に要するコストとして妥当な額程度の費用で入手できる方法を用意し、それをはっきりと公表しなければなりません。方法として好ましいのはインターネットを通じての無料ダウンロードです。ソースコードは、プログラマがプログラムを改変しやすい形式でなければなりません。意図的にソースコードを分かりにくくすることは許されませんし、プリプロセッサや変換プログラムの出力のような中間形式は認められません。)
バイナリファイルの頒布だけでフォントがオープンソースであると見做されるのは、フォントにおいてはソースコードという定義をその文字通りの意味で捉えるのではなく、「改変を加えるために好ましい形式」(preferred form of making modifications)を事実上のソースコードとして見做しているからである。OpenType等のフォント形式は完全に仕様が公開され、FontForgeといったツールを使用することでフォントを解析、編集することができる。つまり、根本的な「改変」や「派生物の作成」が可能であり、実際にバイナリのフォントファイルをそのまま編集することが一般的となっている。つまり、このような事実からバイナリファイルであっても「改変を加えるために好ましい形式」と言え、ソースコードとしての要件を満たすと言えるのだろう。バイナリファイルだけではマスターデータに存在するデザインの意図等の深い情報が欠けることになり、厳密には改変や研究の自由が一部制限されているはずであるが、それでも一般的にはそれで十分に改変と研究の自由を満たしたオープンソースであるという現実的な判断がなされているのである。
よって、1節にて提示した Aa – Ab – Bb – Ba の直線の尺度上において、AIシステムがオープンソースであるために必要なデータに関する条件の境界線としては、完全なデータの公開を求めない左側の領域にあるBbに近い所に線引きされると考える。これはOSIが作成したOSAID v1.0におけるデータ情報の要件に近いものである。
Meta Platforms社のLlamaモデルならびにLlamaライセンス契約(Llama Community License Agreement)がオープンソースに全く該当しないことは既に解説した通りであるが、Llamaライセンス契約にはオープンソースであるか否かという観点において直接的に関係せず、実用に際して予期せぬライセンスの終了にも繋がりかねない幾つかの重大な問題が潜んでいると考えられる。Llamaのオープンソース性に関する論考と重複する部分も多く含まれるが、ここではそれらの問題に対する危険性について雑多に解説する。
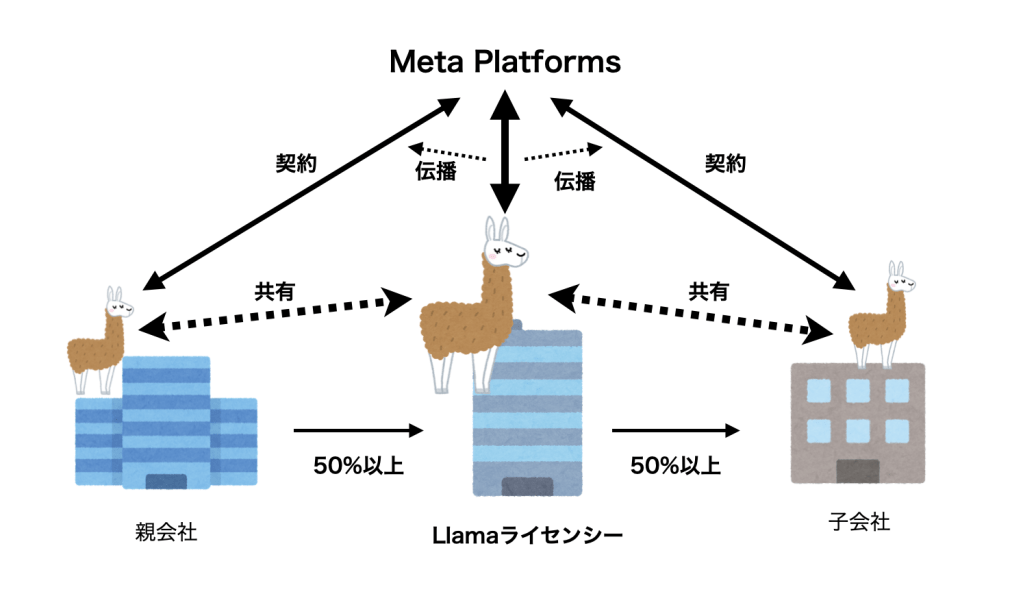
セクション 2 条文 “If, on the Llama 3.1 version release date, the monthly active users of the products or services made available by or for Licensee, or Licensee’s affiliates, is greater than 700 million monthly active users in the preceding calendar month, you must request a license from Meta …” (Llama 3.1のバージョンリリース日において、ライセンシーまたはライセンシーの関連会社によって、もしくはライセンシーまたはライセンシーの関連会社に対して提供される製品またはサービスの月間アクティブユーザー数が直前の暦月において7億人を超える場合、あなたはMetaからのライセンスを要求しなければならず、)
なお、企業グループ内のMAUを色々細かく数字を整えて何とか7億MAU以下にみせかける資料を作って備えたとしても、例えばCEOやCFOが業績発表会等で7億MAUを越えていることを公言していた場合、それは米国法における「利益に反する自白」(Admission against interest)として扱われ、訴訟において他の証拠よりも重要な非常に強い証拠となり得ると考えられる。結局のところ、Meta社からすれば自社を脅かす程度にまで成長しそうな企業にはLlamaを無料で使わせたくないのであり、ここでの検討は特に関係なく、Meta社の一存で「制限を超えているので契約終了」と主張する権限を契約で持たせている以上、大きなコングロマリットを形成する企業グループ内でLlamaを利用することは避けたほうが無難なのだろう。
セクション 1.b.iv 条文 “iv. Your use of the Llama Materials must comply with applicable laws and regulations (including trade compliance laws and regulations) and adhere to the Acceptable Use Policy for the Llama Materials (available at https://llama.com/llama3_1/use-policy), which is hereby incorporated by reference into this Agreement.” (iv. あなたによるLlamaマテリアルの使用は、適用される法律および規制(貿易コンプライアンスに関する法律および規制を含む)を遵守し、Llamaマテリアルに関する利用規約(https://llama.meta.com/llama3_1/use-policy で入手可能)に従う必要があります。このポリシーは、参照することによって本契約に組み込まれます。)
しかし、これを契約内の他の条項と併せて読むと様相が異なってくる。セクション 1.b.ivでは、Llamaマテリアルの使用に際して利用規約(AUP: Acceptable Use Policy)を遵守することが求められている。この条文だけではあくまでライセンシーだけを対象としているように読めるが、セクション 2と併せて読むと「あなたによるLlamaマテリアルの使用」(Your use of the Llama Materials)には関連会社による使用も含まれるのではないかという疑問が出てくる。
セクション 1.b.iv.条文 “iv. Your use of the Llama Materials must comply with applicable laws and regulations (including trade compliance laws and regulations) and adhere to the Acceptable Use Policy for the Llama Materials (available at https://llama.com/llama3_1/use-policy), which is hereby incorporated by reference into this Agreement.” (iv. あなたによるLlamaマテリアルの使用は、適用される法律および規制(貿易コンプライアンスに関する法律および規制を含む)を遵守し、Llamaマテリアルに関する利用規約(https://llama.meta.com/llama3_1/use-policy で入手可能)に従う必要があります。このポリシーは、参照することによって本契約に組み込まれます。)
“h. Engage in any action, or facilitate any action, to intentionally circumvent or remove usage restrictions or other safety measures, or to enable functionality disabled by Meta” (使用制限またはその他の安全対策を故意に回避または削除する行為、または無効化された機能を使用可能にする行為を行うこと、またはそのような行為を助長すること) “5. Interact with third party tools, models, or software designed to generate unlawful content or engage in unlawful or harmful conduct and/or represent that the outputs of such tools, models, or software are associated with Meta or Llama 3.2” (違法なコンテンツの生成、違法または有害な行為を目的として設計された第三者のツール、モデル、ソフトウェアと相互に作用すること、および/または、そのようなツール、モデル、ソフトウェアの出力がMetaまたはLlamaに関連していると表明すること)
“With respect to any multimodal models included in Llama 3.2, the rights granted under Section 1(a) of the Llama 3.2 Community License Agreement are not being granted to you if you are an individual domiciled in, or a company with a principal place of business in, the European Union.” (Llama 3.2に含まれるマルチモーダルモデルに関して、あなたがEUに居住する個人または主たる事業所をEUに置く企業である場合、Llama 3.2コミュニティ・ライセンス契約のセクション1.aに基づいて付与される権利はあなたへ付与されません。)
セクション 7条文: “7. Governing Law and Jurisdiction. This Agreement will be governed and construed under the laws of the State of California without regard to choice of law principles, and the UN Convention on Contracts for the International Sale of Goods does not apply to this Agreement. The courts of California shall have exclusive jurisdiction of any dispute arising out of this Agreement.” (7. 準拠法および管轄権: 本契約は、法の選択に関する原則に関わらず、カリフォルニア州法に準拠し、解釈されるものとし、国際物品売買契約に関する国連条約は本契約には適用されないものとします。本契約に起因する紛争に関しては、カリフォルニア州の裁判所が排他的管轄権を有するものとします。)
“Llama 3.2” means the foundational large language models and software and algorithms, including machine-learning model code, trained model weights, inference-enabling code, training-enabling code, fine-tuning enabling code and other elements of the foregoing distributed by Meta at https://llama.com/llama-downloads. (「Llama 3.2」とは、Metaが https://llama.meta.com/llama-downloads で頒布する機械学習モデルコード、トレーニングモデルの重み、推論を可能にするコード、トレーニングを可能にするコード、ファインチューニングを可能にするコード、およびこれらに付随するその他の要素を含む、大規模言語モデルおよびソフトウェアおよびアルゴリズムを指します。) “Llama Materials” means, collectively, Meta’s proprietary Llama 3.2 and Documentation (and any portion thereof) made available under this Agreement. (「Llamaマテリアル」とは、本契約の下で提供されるMeta独自のLlama 3.2およびドキュメンテーション(およびその一部)を総称して指します。)
“i. If you distribute or make available the Llama Materials (or any derivative works thereof), or a product or service (including another AI model) that contains any of them, you shall (A) provide a copy of this Agreement with any such Llama Materials; and (B) prominently display “Built with Llama” on a related website, user interface, blogpost, about page, or product documentation. If you use the Llama Materials or any outputs or results of the Llama Materials to create, train, fine tune, or otherwise improve an AI model, which is distributed or made available, you shall also include “Llama” at the beginning of any such AI model name.” (i. あなたがLlamaマテリアル(またはその派生作品)またはLlamaマテリアルを含む製品やサービス(他のAIモデルを含む)を頒布もしくは利用可能にする場合、あなたは (A) 当該のLlamaマテリアルとともに本契約書の写しを提供し、(B) 関連するWebサイト、ユーザーインターフェース、ブログ投稿、概要ページ、または製品ドキュメントに「Built with Llama」を明示的に表示しなければなりません。LlamaマテリアルまたはLlamaマテリアルの出力若しくは結果を使用して、AIモデルを作成、トレーニング、ファインチューニング、または改良し、それを頒布する場合、そのAIモデル名の先頭に「Llama」を含めるものとします。)
ライセンスの権利と再頒布 a. 権利の付与: あなたは、Llamaマテリアルに含まれるMetaの知的財産またはその他の権利に基づいて、Llamaマテリアルを使用、再製、頒布、コピー、派生作品の作成、および改変するための非独占的、世界的、譲渡不可能でロイヤルティフリーの限定的なライセンスが付与されます。
b. 再頒布と使用: i. あなたがLlamaマテリアル(またはその派生作品)またはLlamaマテリアルを含む製品やサービス(他のAIモデルを含む)を頒布もしくは利用可能にする場合、あなたは (A) 当該のLlamaマテリアルとともに本契約書の写しを提供し、(B) 関連するWebサイト、ユーザーインターフェース、ブログ投稿、概要ページ、または製品ドキュメントに「Built with Llama」を明示的に表示しなければなりません。LlamaマテリアルまたはLlamaマテリアルの出力若しくは結果を使用して、AIモデルを作成、トレーニング、ファインチューニング、または改良し、それを頒布する場合、そのAIモデル名の先頭に「Llama」を含めるものとします。
ii. あなたがライセンシーから統合エンドユーザー製品の一部としてLlamaマテリアルまたはその派生作品を受け取った場合、本契約の第2条はあなたに適用されません。
iv. あなたによるLlamaマテリアルの使用は、適用される法律および規制(貿易コンプライアンスに関する法律および規制を含む)を遵守し、Llamaマテリアルに関する利用規約(https://llama.meta.com/llama3_1/use-policy で入手可能)に従う必要があります。このポリシーは、参照することによって本契約に組み込まれます。
知的財産: a. 本契約の下で商標ライセンスは付与されず、Llamaマテリアルに関連して、Metaまたはライセンシーのいずれも他方またはその関連会社が所有する、またはそれらに関連する名称または商標を使用することはできません。ただし、Llama素材を合理的かつ慣例的に説明し再頒布するために必要な場合、または本第5条(a)項に定める場合を除きます。Metaは、本契約により、第1条b項iの最後の文章に従うために必要な場合のみ、「Llama」(「マーク」)を使用するライセンスを貴社に付与します。あなたはMetaのブランドガイドライン(現在は https://about.meta.com/brand/resources/meta/company-brand/ でアクセス可能)を遵守するものとします。マークの使用から生じるすべてののれんは、Metaに帰属するものとします。
b. Metaが作成したLlamaマテリアルおよびMetaによるまたはMetaのための派生物の所有権に従い、あなたが作成したLlamaマテリアルの派生作品および改変作品に関しては、あなたとMetaの間で、あなたは現在および今後もそれらの派生作品および改変作品の所有者となります。
c. あなたがMetaまたは他の法人に対して、訴訟またはその他の手続き(訴訟における反訴または反論を含む)を起こし、LlamaマテリアルまたはLlama 3.1の出力や結果、またはいずれかの一部があなたの所有またはライセンス付与可能な知的財産権またはその他の権利を侵害していると申し立てる場合、訴訟または申し立てが提起または開始された時点で、本契約に基づきあなたに付与されたライセンスは終了するものとします。あなたは、Llamaマテリアルの使用または頒布に起因もしくは関連する第三者からの請求について、Metaを免責し、損害を与えないものとします。
法律または他者の権利を侵害する行為、具体的には以下を含みます: a. 以下の違法または不法な活動またはコンテンツに関与、促進、作成、寄与、奨励、計画、扇動、または助長すること。 i. 暴力若しくはテロ行為 ii. 児童搾取的コンテンツの勧誘、作成、取得、または普及、または児童性的虐待的コンテンツの報告の不履行を含む児童に対する搾取または危害 iii. 人身売買、搾取、および性的暴力 iv. 未成年者に対する情報または素材の違法な配布(わいせつな素材を含む)、またはそのような情報または素材に関連して法的に要求される年齢制限の適用を怠ること。 v. 性的勧誘 vi. その他の犯罪行為 b. 個人または個人グループに対する嫌がらせ、虐待、脅迫、またはいじめへの関与、促進、扇動、または促進 c. 雇用、雇用手当、信用クレジット、住宅、その他の経済的利益、またはその他の必要不可欠な商品およびサービスの提供における差別またはその他の不法または有害な行為の関与、促進、扇動、または促進 d. 金融、法律、医療/健康、または関連する専門的業務を含むがこれらに限定されない、あらゆる専門職の無許可または無免許の業務に従事する e. 適用される法律で要求される権利および同意なしに、個人に関する健康健康、人口統計情報、またはその他の機密性の高い個人情報またはプライバシー情報を収集、処理、開示、生成、または推測すること f. Lamaマテリアルを使用した製品またはサービスの成果または結果を含む、第三者の権利を侵害、不正利用、またはその他の方法で侵害する行為に関与または容易にしたり、コンテンツを作成したりすること g. 悪意のあるコード、マルウェア、コンピュータウイルスを作成、生成、またはその作成を容易にしたり、Webサイトまたはコンピュータシステムの適切な動作、完全性、操作、または外観を無効にしたり、過剰な負荷をかけたり、妨害したり、損なったりする可能性のあるその他の行為を行うこと h. 使用制限またはその他の安全対策を故意に回避または削除する行為、またはMetaによって無効化された機能を使用可能にする行為を行うこと、またはそのような行為を助長すること
以下の内容に関連するLama 3.2の使用を含め、個人に対して死亡または身体的な危害のリスクをもたらす活動の計画または開発に従事、もしくはそのような活動を宣伝、扇動、助長、支援すること a. 軍事、戦争、原子力産業またはその用途、スパイ行為、米国国務省が管理する国際武器取引規則(ITAR)の対象となる物品または活動への使用 b. 銃および違法な武器(武器開発を含む) c. 違法薬物および規制・管理物質 d. 重要なインフラストラクチャ、輸送技術、または大型機械の運用 e. 自傷または他者への危害(自殺、自傷行為、摂食障害を含む) f. 暴力、虐待、または個人に対する身体的危害を扇動または助長する意図を持つコンテンツ
以下に関連するLama 3.2の使用を含め、故意に他人を欺いたり、誤解を招くような行為 a. 詐欺行為、または偽情報の作成、宣伝、促進、または助長する行為 b. 中傷的な発言、画像、その他のコンテンツの作成を含む、中傷的なコンテンツの生成、促進、または助長 c. スパムの生成、宣伝、または配布の助長 d. 同意、承認、法的権利なく他者を装うこと e. Llama 3.2の使用または出力が人間による生成であると表明すること f. 偽のレビューやその他の偽のオンラインエンゲージメント手段を含む、偽のオンラインエンゲージメントの生成または助長
Meta Platforms社が開発するAIモデルのシリーズである「Llama」は、高性能で費用対効果が高く、比較的寛容な条件で頒布されていると多くの人々から見做されていることからシステムへの採用や派生モデルの開発等の利用が拡大しているように見受けられる。しかし、Meta社のCEOが自ら「Llamaはオープンソースである」と喧伝することで本当にLlamaがオープンソースであると誤解する傾向もあり、またLlamaライセンス契約自体に幾つかの厄介な問題が潜んでいるにも関わらず採用が進むことで今後法的な問題が生じかねないと考えられる。そこで本稿では、先ずLlamaライセンス契約のオープンソースへの適合性から解説することとする。 なお、Llamaライセンス契約のモデル利用時における注意点に関しては別の記事とする。
セクション 2 条文 “If, on the Llama 3.1 version release date, the monthly active users of the products or services made available by or for Licensee, or Licensee’s affiliates, is greater than 700 million monthly active users in the preceding calendar month, you must request a license from Meta …” (Llama 3.1のバージョンリリース日において、ライセンシーまたはライセンシーの関連会社によって、もしくはライセンシーまたはライセンシーの関連会社に対して提供される製品またはサービスの月間アクティブユーザー数が直前の暦月において7億人を超える場合、あなたはMetaからのライセンスを要求しなければならず、)
セクション 1.b.iv 条文 “Your use of the Llama Materials must … adhere to the Acceptable Use Policy for the Llama Materials (available at https://llama.meta.com/llama3_1/use-policy), which is hereby incorporated by reference into this Agreement.” (Llamaマテリアルに関する利用規約(https://llama.meta.com/llama3_1/use-policy で入手可能)に従う必要があります。このポリシーは、参照することによって本契約に組み込まれます。)
Meta社はLlamaモデルの使用者がモデルの使用に際して遵守すべき事項を利用規約(Acceptable Use Policy)として別途定めており、セクション 1.b.ivではこの利用規約が「参照によってLlamaライセンス契約に組み込まれる」ことを規定している。この契約に「組み込まれる」ということは契約の一部となるということであり、つまり利用規約はライセンス契約の拡張された一部ということになる。
利用規約では、おおまかに (1)法律に反する利用または第三者の権利を害する利用、(2)個人に死亡または身体的侵害のリスクをもたらす活動の企画・開発に従事し、もしくはこれを促進、扇動、促進、支援すること、(3)意図的に他人を欺いたり、誤解させたりする利用、(4)AIシステムの既知の危険性をエンドユーザーに適切に開示しないこと、といった行為を禁止することが定められている。これらの行為が社会的に望ましくない行為であることは事実であるが、こういったいわば倫理的条項と言える条文で一般的に合法であるはずの行為まで利用の制限を行うことはOSD 6条の「利用する分野(fields of endeavor)に対する差別の禁止」に抵触する。
“With respect to any multimodal models included in Llama 3.2, the rights granted under Section 1(a) of the Llama 3.2 Community License Agreement are not being granted to you if you are an individual domiciled in, or a company with a principal place of business in, the European Union.” (Llama 3.2に含まれるマルチモーダルモデルに関して、あなたがEUに居住する個人または主たる事業所をEUに置く企業である場合、Llama 3.2コミュニティ・ライセンス契約のセクション1.aに基づいて付与される権利はあなたへ付与されません。)
h. Engage in any action, or facilitate any action, to intentionally circumvent or remove usage restrictions or other safety measures, or to enable functionality disabled by Meta (使用制限またはその他の安全対策を故意に回避または削除する行為、または無効化された機能を使用可能にする行為を行うこと、またはそのような行為を助長すること) 5. Interact with third party tools, models, or software designed to generate unlawful content or engage in unlawful or harmful conduct and/or represent that the outputs of such tools, models, or software are associated with Meta or Llama 3.2 (違法なコンテンツの生成、違法または有害な行為を目的として設計された第三者のツール、モデル、ソフトウェアと相互に作用すること、および/または、そのようなツール、モデル、ソフトウェアの出力がMetaまたはLlamaに関連していると表明すること)
セクション 1.b.i 条文 “Prominently display “Built with Llama.”” (「Built with Llama」を明示的に表示しなければなりません) “If you use the Llama Materials or any outputs or results of the Llama Materials to create, train, fine tune, or otherwise improve an AI model, which is distributed or made available, you shall also include “Llama” at the beginning of any such AI model name.” (LlamaマテリアルまたはLlamaマテリアルの出力若しくは結果を使用して、AIモデルを作成、トレーニング、ファインチューニング、または改良し、それを頒布する場合、そのAIモデル名の先頭に「Llama」を含めるものとします。)
セクション 1.b.iは派生作品を頒布する際にLlamaライセンス契約のテキストを添付することに加え、「Built with Llama」という文言を製品のWebページやドキュメント等に目立つように表示することと派生モデルの名称の先頭に「Llama」を含めることを強制している。これは、OSD 8条の「特定製品でのみ有効なライセンスの禁止」に抵触するだろう。通常、オープンソースであるライセンスは著作権の帰属表示を正しく表示することを求めるが、Llamaライセンス契約のように特定の名称やブランディングを強制せず、自由な派生と再頒布を認めている。つまり、Llamaはこの点で派生と頒布の自由を妨げていると言える。
セクション 1.b.i 条文 “If you use the Llama Materials or any outputs or results of the Llama Materials to create, train, fine tune, or otherwise improve an AI model, which is distributed or made available, you shall also include “Llama” at the beginning of any such AI model name.” (LlamaマテリアルまたはLlamaマテリアルの出力若しくは結果を使用して、AIモデルを作成、トレーニング、ファインチューニング、または改良し、それを頒布する場合、そのAIモデル名の先頭に「Llama」を含めるものとします。)
このような意見を意見を封じることも目的に含め、私を含む世界の有志が2年間の共同設計プロセスを経て「オープンソースAIの定義」(OSAID: Open Source AI Definition)を2024年10月までに作り上げた。OSAIDはモデル、コード、データと様々なコンポーネントから構成されるAIシステムがオープンソースAIを名乗るための条件と言えるものであり、モデル単体のようなコンポーネント単位でのオープンソース性を判断するものではない。しかし、その策定プロセス中において「AIモデルにおけるソースコードとは何か?」という疑問は当然ながら幾度も議論された。その議論において、AIトレーニングという演算における最終的な結果物であるモデルには世界の多くの法域における解釈ではトレーニングデータに発生している知的財産権が残存せず、さらに、データ自身がモデルを制御しているわけでもないことから、トレーニングデータがAIモデルのソースコードと言えるかは疑問視する見方が強かったと思う。そうは言っても、トレーニング過程からを含めて全てのソースコードとウェイトを含むモデルの実体が完全にオープンソースの定義の根本的理念に適合し、さらに全てのトレーニングデータに完全な透明性があることは、AIシステムがオープンソースと見做す上でコンセンサスが取れている考え方である。そして、これはほぼそのままOSAIDの考え方でもある。
a. 権利の付与: あなたは、Llamaマテリアルに含まれるMetaの知的財産またはその他の権利に基づいて、Llamaマテリアルを使用、再製、頒布、コピー、派生作品の作成、および改変するための非独占的、世界的、譲渡不可能でロイヤルティフリーの限定的なライセンスが付与されます。
b. 再頒布と使用:
i. あなたがLlamaマテリアル(またはその派生作品)またはLlamaマテリアルを含む製品やサービス(他のAIモデルを含む)を頒布もしくは利用可能にする場合、あなたは (A) 当該のLlamaマテリアルとともに本契約書の写しを提供し、(B) 関連するWebサイト、ユーザーインターフェース、ブログ投稿、概要ページ、または製品ドキュメントに「Built with Llama」を明示的に表示しなければなりません。LlamaマテリアルまたはLlamaマテリアルの出力若しくは結果を使用して、AIモデルを作成、トレーニング、ファインチューニング、または改良し、それを頒布する場合、そのAIモデル名の先頭に「Llama」を含めるものとします。
ii. あなたがライセンシーから統合エンドユーザー製品の一部としてLlamaマテリアルまたはその派生作品を受け取った場合、本契約の第2条はあなたに適用されません。
iv. あなたによるLlamaマテリアルの使用は、適用される法律および規制(貿易コンプライアンスに関する法律および規制を含む)を遵守し、Llamaマテリアルに関する利用規約(https://llama.meta.com/llama3_1/use-policy で入手可能)に従う必要があります。このポリシーは、参照することによって本契約に組み込まれます。
a. 本契約の下で商標ライセンスは付与されず、Llamaマテリアルに関連して、Metaまたはライセンシーのいずれも他方またはその関連会社が所有する、またはそれらに関連する名称または商標を使用することはできません。ただし、Llama素材を合理的かつ慣例的に説明し再頒布するために必要な場合、または本第5条(a)項に定める場合を除きます。Metaは、本契約により、第1条b項iの最後の文章に従うために必要な場合のみ、「Llama」(「マーク」)を使用するライセンスを貴社に付与します。あなたはMetaのブランドガイドライン(現在は https://about.meta.com/brand/resources/meta/company-brand/ でアクセス可能)を遵守するものとします。マークの使用から生じるすべてののれんは、Metaに帰属するものとします。
b. Metaが作成したLlamaマテリアルおよびMetaによるまたはMetaのための派生物の所有権に従い、あなたが作成したLlamaマテリアルの派生作品および改変作品に関しては、あなたとMetaの間で、あなたは現在および今後もそれらの派生作品および改変作品の所有者となります。
c. あなたがMetaまたは他の法人に対して、訴訟またはその他の手続き(訴訟における反訴または反論を含む)を起こし、LlamaマテリアルまたはLlama 3.1の出力や結果、またはいずれかの一部があなたの所有またはライセンス付与可能な知的財産権またはその他の権利を侵害していると申し立てる場合、訴訟または申し立てが提起または開始された時点で、本契約に基づきあなたに付与されたライセンスは終了するものとします。あなたは、Llamaマテリアルの使用または頒布に起因もしくは関連する第三者からの請求について、Metaを免責し、損害を与えないものとします。
オープンソースAI(Open Source AI)とは、オープンソースの状態にあるAIシステムのことである。これはある意味で自明なのではあるが、「オープンソースの定義」(OSD)を管理している米国の非営利団体Open Source Initiative(OSI)では、2023年からわざわざ新たに「オープンソースAIの定義」(OSAID: Open Source AI Definition)の策定を開始している。2024年の8月頃には定義のRC版が公開される見込みであるが、本稿ではこの新たな定義が何故必要になり、その定義がどのような機能するものであるかということに対し、主に佐渡が視点から時系列的に簡単に紹介していく。これによって日本国内においてOSAIDが認知され、AI開発コミュニティにおいて自由かつ透明性が確保されたシステムの必要性への理解が深まる一助となることを期待する。
AIシステムを審査するために前項で大別したコンポーネントをLF AI+Dataのメンバーらが公表した論文「The Model Openness Framework」に従って細分化したリストを使用し、下記のようにデータの情報、コード、モデルを分類し、それらが満たすべき法的枠組みを個別に指定している。このチェックリストは現状のドラフト0.0.8では定義に含まれている形式の文書となっているが、今後の議論次第でこのチェックリストは定義とは分離される可能性があると私は見ている。AI周辺の技術の進展によってこのような形式の分類が不適当となる将来はそんなに遠くないと思われ、この部分は今後逐次改編される可能性があるからである。
OSAIDの現時点のバージョンは0.0.8であるが、夏にはRC版となり年内にはバージョン1.0として正式にリリースされることになる。現時点では10月にRed Hatの本拠地であるRaleighで開催のAll Things Openにて発表される見込みであるが、そこから若干遅らせる可能性はあるだろう。とは言え、定義全体としては現在の0.0.8でほぼ完成しており、ここから大幅に内容が変更される可能性は低い。しかし、現時点で残されている議論や課題は中々妥協点を探ることは難しく、議論をどのように収束させていくか私から見ても容易ではなさそうなのは懸念される。