DeepSeekは世界に衝撃を与えているが、その要因としては、中国から米国の巨大AIベンダーを脅かす新たな勢力が現れたことに加え、AIモデルがMITライセンスというオープンソースライセンスでも頒布されている点が大きいと考えられる。しかし、DeepSeekはモデルこそMITライセンスで公開しているものの、データ処理コードや肝心のトレーニングデータに関する情報は、現時点では何も公開されておらず、詳しい情報も開示されていない。このような経緯から、「DeepSeekはオープンソースとは言えない」とする意見が各所で盛んに主張されており、「果たしてオープンソースと呼ぶために完全なトレーニングデータの公開は必須なのか」という問いへの関心も、ある程度高まっているように思われる。
昨年10月、Open Source Initiative(OSI)は「オープンソースAIの定義」(OSAID: Open Source AI Definition)を公表しており、それに従えばオープンソースAIであるためには完全なトレーニングデータが存在することは推奨されるものの必須とする要素ではなく、基本的にはトレーニングデータの詳細な情報があれば済むという定義となっている。現状ではこのOSIの方針は妥当な考え方であるとの見方が強いと考えているが、その一方で「完全なトレーニングデータの公開を必要とする論」及び「データの公開は全く必要としない論」の相反する二つの考え方が根強くある。本稿ではその対立の背景を踏まえつつ、OSIの考え方が導き出されるまでの解釈を説明する。
なお、この解釈は佐渡個人が今までの議論を踏まえて、個人としての現在の解釈を整理して解説するものであり、実際の議論がこのような過程を踏まえたわけではないことは留意して頂きたい。
English Version: https://shujisado.org/2025/02/18/should-open-source-ai-mean-exposing-all-training-data/

- 1. トレーニングデータの必要性に関する対立の構図
- 2. AI領域におけるOSD 2条「ソースコード」の探究
- 3. 思想、法制、技術の観点からのトレーニングデータの必要性の検討
- 4. データ要件に関する将来の展望
- 5. 最後に
1. トレーニングデータの必要性に関する対立の構図
AIシステムがオープンソースであるための条件を考えると、誰もが先ずモデルそのものへオープンソースライセンスが適用されていることを条件とするだろう。ただ、AIの場合、その条件だけではAIの動作を完全に解明することは困難であり、研究と改変の自由を実現することは難しい。よって、その他の要素も必要とし、AIのトレーニングからモデルの実行までの過程で使用された全てのコードがオープンソース化されることも条件とする考え方が生まれる。ここまではオープンソースのライセンスに関する知識を少し持っている者であれば、ほぼ同意するだろう。しかし、そのトレーニングで使用された実際のデータとなると、その完全な公開を求める陣営と公開を必要としない陣営に分かれることになる。中でも全てをパブリックドメインやオープンデータを使用することを条件とする考え方とデータの詳細な情報すら一切必要としない考え方ではあまりにも隔たりが大きく、相互に妥協することは困難となる。困ったことに双方を支持する声は無視できるほどには小さくないのが現実であり、極端な声に押される形で各所で論争の火種となっていることは事実だろう。
そこでトレーニングデータに関する意見を整理すると、大まかには下記四つの主張に分類されるのではないかと思う。
- A. 完全なトレーニングデータの必要性を主張する派:
- Aa. 全てのデータをオープンデータとする論:
全てのトレーニングにおいてオープンデータ若しくはパブリックドメインのデータセットを使用し、モデル作成のあらゆる側面の透明性が確保され、かつ一から再製可能であることを保証する必要があるという主張 - Ab. 一般に入手できる公開データを必須とする論:
全てのトレーニングデータ全体を誰でもダウンロードできるように公開し、モデルを正確に再現できるようにする必要があるとする主張
- Aa. 全てのデータをオープンデータとする論:
- B. 完全なトレーニングデータを必要としない派:
- Ba. データを一切必要なしとする論:
追加学習や微調整を行うことで改変や派生ができるため、元々のトレーニングデータ全ての共有が必須ではないとする主張 - Bb. データの出処等の詳細な情報を開示すれば良いとする論:
類似のデータを複製または入手できるのであれば、データがどのように取得されたか等の詳細な情報が必要であると主張し、元のデータセットを完全に開示する必要はないとする主張
- Ba. データを一切必要なしとする論:
この四つの主張はデータの完全性という一つの直線の尺度の上にプロットして並べていくと、データの完全性が高い順に Aa – Ab – Bb – Ba という並びになるのだろう。オープンソースであるかどうかということはYesかNoの二値で表現するしかない問題であり、よってこの尺度の上のどこかにオープンソースとして認める明確なラインを引くことになる。

しかし、この四つの主張はいずれにも即座に反論を唱えることできるので話がややこしくなる。
真に「オープンなデータ」を要求した場合、利用可能なデータセットは大幅に縮小され、現時点で大規模なモデルとされる規模のAI開発でオープンソースでは不可能になる可能性が生じるだろう。また、ヘルスケアや教育等の多くの専門領域においては法律上または倫理的に制限されたデータが含まれており、それらのデータはそのまま共有できないため、公開データのみにこだわることはAIを必要とする重要な領域からオープンソースAIが除外されるということに繋がる。一方、トレーニングデータがないと再現性と徹底的なモデルの監査はほぼ不可能になり、バイアスを検出したり、研究や改善のために結果を再現することが妨げられることになる。正確な再現性や詳細なデバッグには実際のデータセットへのアクセスが必要という反論には説得力があるように考えられる。
意見を4つに分類することで Aa – Ab – Bb – Baの尺度のどこかにオープンソースAIであると認めるラインを引かねばならないということだけははっきりしているが、どこにそのラインを引くかはもっと原理原則に立ち返って詳細に検討しなければならない。
2. AI領域におけるOSD 2条「ソースコード」の探究
トレーニングデータの完全性をどこまで求めるかを詳細に検討するためには、やはり「オープンソースの定義」(OSD: Open Source Definition)という根本的な原則に基づいて考える必要がある。現在のOSDのバージョンは2004年にリリースされた1.9であり、20年以上変更がない。オープンソースであるための条件として完全に安定化していると言えるだろう。そして、このOSDをAIシステムに対して適用する場合、問題となるのは下記の第2条「ソースコード」である。
OSD Section 2. Source Code:
The program must include source code, and must allow distribution in source code as well as compiled form. Where some form of a product is not distributed with source code, there must be a well-publicized means of obtaining the source code for no more than a reasonable reproduction cost, preferably downloading via the Internet without charge. The source code must be the preferred form in which a programmer would modify the program. Deliberately obfuscated source code is not allowed. Intermediate forms such as the output of a preprocessor or translator are not allowed.
(オープンソースであるプログラムはソースコードを含んでいなければならず、コンパイル済形式と同様にソースコードでの頒布も許可されていなければなりません。何らかの事情でソースコードと共に頒布しない場合には、ソースコードを複製に要するコストとして妥当な額程度の費用で入手できる方法を用意し、それをはっきりと公表しなければなりません。方法として好ましいのはインターネットを通じての無料ダウンロードです。ソースコードは、プログラマがプログラムを改変しやすい形式でなければなりません。意図的にソースコードを分かりにくくすることは許されませんし、プリプロセッサや変換プログラムの出力のような中間形式は認められません。)
OSD 第2条では、オープンソースである条件としてソースコードが自由に入手可能でなければならないことを規定している。通常のソフトウェアであれば、実行ファイル形式のバイナリファイルに対して改変の許諾がなされていたとしても、技術的には自由に改変できるとは言えない。プログラマが通常扱うソースコード形式のファイルが入手できなければ、自由に改変や派生の自由が確保されていると言えないことは自明であるだろう。基本的にAIモデルはウェイトやパラメータと呼ばれる数値データを保存したバイナリファイルであるので、素直に考えればAIモデルそのものだけではソースコードが存在しないと言える。
しかし、ここである領域におけるオープンソース性の判断のケースを思い出さなければならない。オープンソースのフォントである。オープンソースのフォントとして知られるSIL OFL適用のフォントは、実際どのような形式で頒布されているだろうか。多くの場合、OpenTypeやTrueType形式のファイルで配布されており、これらは文字のアウトラインやメタデータが格納されたバイナリ形式である。フォントにはソフトウェアのソースコードに相当するマスターデータ(テキスト形式)が存在する場合もあるが、それがなくとも、バイナリ形式だけでオープンソースと見做されているのが実情だ。
バイナリファイルの頒布だけでフォントがオープンソースであると見做されるのは、フォントにおいてはソースコードという定義をその文字通りの意味で捉えるのではなく、「改変を加えるために好ましい形式」(preferred form of making modifications)を事実上のソースコードとして見做しているからである。OpenType等のフォント形式は完全に仕様が公開され、FontForgeといったツールを使用することでフォントを解析、編集することができる。つまり、根本的な「改変」や「派生物の作成」が可能であり、実際にバイナリのフォントファイルをそのまま編集することが一般的となっている。つまり、このような事実からバイナリファイルであっても「改変を加えるために好ましい形式」と言え、ソースコードとしての要件を満たすと言えるのだろう。バイナリファイルだけではマスターデータに存在するデザインの意図等の深い情報が欠けることになり、厳密には改変や研究の自由が一部制限されているはずであるが、それでも一般的にはそれで十分に改変と研究の自由を満たしたオープンソースであるという現実的な判断がなされているのである。
このフォントのオープンソース性の判断から教訓となるのは下記の二点であろう。
- OSDにおける「ソースコード」とは厳密にソースコードそのものを指すのではなく、あくまで開発者がオープンソースである対象物を改変や研究しやすい「改変を加えるために好ましい形式」であることを指す。
- 開発コミュニティにとって十分に機能する程度の「改変と研究の自由」が確保されているのであれば、一部の情報が欠けた不完全な状態でもオープンソースとして許容される。
前者は、ライセンスの対象物を作成するための材料とも言えるもの全てを揃える必要性はなく、材料を加工済みの形式でも許容されるということを示している。これは一見、バイナリのAIモデルさえ存在していればOSDのソースコード要件を満たすという主張を強化するように感じる。しかし、フォントの場合はバイナリのフォントファイルの中にグリフのアウトラインが全て収まっており、それを編集する手段もあるので事実上ソースファイルと呼べるのに対し、AIモデルの場合にはモデルの動作を完全に再トレーニングしたり大幅に改変したりする場合には全てのデータ前処理ロジックが必要になることもある。よって、AIモデルだけでは「改変を加えるために好ましい形式」には該当せず、前節でのBaに該当する「データを一切必要なしとする論」は不十分であると言えるのだろう。
後者は、開発者のための「改変と研究の自由」が十分に確保されているのであれば、その自由の実現に直接関係しない情報やオブジェクトが必要とは限らないことを示す。フォントの場合でもマスターデータにしか存在しないデザインの意図のような情報は必須とはされていないし、他の領域でも例えばプロプライエタリなコンパイラ等の開発環境やクラウド等の商用サービス環境を必要とするソフトウェアであってもそのコードに「改変と研究の自由」があればオープンソースである。このような事実を総合して考えれば、前節でのAaに該当する「全てのトレーニングデータをオープンデータとする論」は過大過ぎる要求であるとは言えるだろう。確かに全ての材料を構成する情報やオブジェクトがオープンな条件で入手できることは完全な「研究」にとって重要かもしれないが、再現性の確保のために全部の材料が自由に手に入る必要はないのである。
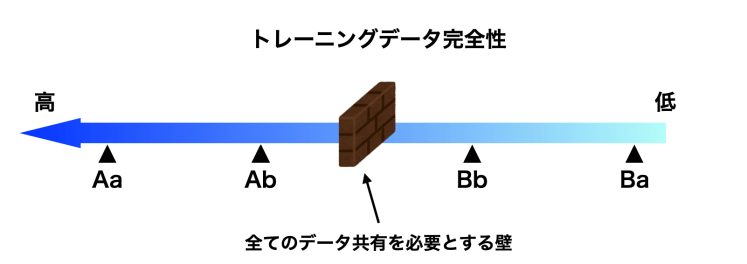
ここまでのOSD 2条「ソースコード」の要件の探究により、オープンソースのAIのために必須となるトレーニングデータの要件は「改変を加えるために好ましい形式」であることが見えてきた。また、開発コミュニティにとって十分に機能する程度の「改変と研究の自由」が確保されるラインは前節の尺度における両端の論の周辺ではなく、Ab-Bbの二つの論のどこかにあることも見えてくる。しかし、このAb-Bbの間には完全なトレーニングデータを必要とするかしないかという全く相反する考え方のラインが存在する。このどちら側にオープンソースAIとしてみなすラインを引くかという問いに答えを出すには更なる詳細な検討をしなければならない。
3. 思想、法制、技術の観点からのトレーニングデータの必要性の検討
「改変と研究の自由」が確保される「改変を加えるために好ましい形式」を実現するラインがAb-Bb間のどのあたりに存在するのか検討するためには、結局の所その中間にあるトレーニングデータを必要とするかしないかという壁から見て左右のどちら側なのかを検討することになる。オープンソースとは自由を求める思想や哲学であり、著作権という法的な権利に基づいた概念であり、ソフトウェアの技術領域における考え方であるわけなので、それぞれ思想面、法制面、技術面の三つの要素から詳細に検討する。
3.1. 思想面からの検討
先ず、思想面からの検討については様々な観点が浮かぶが、下記のようにトレーニングデータの必要性の両論を整理できるだろう。
トレーニングデータのソースコード性
前節までにOSD 2条におけるソースコードとは「改変を加えるために好ましい形式」であることは明らかとなっているが、この定義によって誰もが対象となる何かを研究し、フォークし、改善することが可能となっている。この考え方を援用すれば、AIモデルの機能や性能がトレーニングデータによって決定的に決まる場合、思想的にはトレーニングデータが極めてソースコードに類似するものと言える。このデータが完全にオープンであるのであれば、正確にモデルを再製し、バイアスを精査し、完全に研究を行って結果を確認することもできるだろう。
その一方、トレーニングデータによってモデルの機能や性能が決定的には決まらず、類似のデータやその他のデータを使用して微調整または再トレーニングを行うことができるのであれば、事実上フォークを可能としているとも言える。また、バイアスの精査を含めた研究もトレーニング用のデータセットが収集された場所と方法、フィルタリングの方法などに関する詳細な指示等の詳細な情報さえ把握できれば、必要に応じて同等のデータセットを再構成し、オープンソースである派生物を作成する自由が維持されるとも考えられる。
透明性と倫理的な説明責任
トレーニングデータが全てオープンに利用できるのであれば、それは完全に透明性が確保されていると言える。また、全てのデータを公開するということは、非倫理的な手法で収集されたデータも明らかにできるということであり、コミュニティによる監視も可能になる。例えば、トレーニング用のデータセットに著作権で保護された素材やプライバシーに配慮が必要な素材が適用法上における適切な許可なく含まれていた場合、その問題を明らかにすることに役立ち、修正や法的措置が促されることになるだろう。
これに対し、確かに全てのデータが揃っているのであれば透明性等の倫理的な面にはメリットがあることは間違いないものの、そもそもオープンソースであるための要件にそれが必要であるかという問題が発生するだろう。極論すれば悪い目的であってもオープンソースは成り立つのである。また、AIがオープンソースであるために完全なデータを要求した場合、特に医療、金融や教育等の領域における個人のプライバシー情報を扱うことが事実上無理ということになる。トレーニングデータの完全性を求めなければ、それらのセンシティブなデータの共有を義務付けないということになり、プライバシー関連の法を尊重しつつオープンソースを称するというメリットが生まれるだろう。
自由ソフトウェア的な哲学の追求
オープンソースはライセンス判定基準として見ると基本的に自由ソフトウェアとほぼ同義であり、オープンソースにおいても自由ソフトウェアの哲学というものが共有されていると言える。その自由ソフトウェアの哲学的な観点からは、AIモデルの機能や性能に影響を与える全コンポーネントが「自由」であることが必要となるだろう。AIモデルの機能や性能に対してトレーニングデータがある程度の影響を与えることは確実であるわけなので、哲学的にはデータを必要とし、それによって「ユーザーがあらゆる点でソフトウェアを制御する」という基本的な自由の哲学と合致すると言えるだろう。
この哲学的な観点においては、データの完全性を必要としない陣営からはあまり有効な反論はあると思えない。やはり、自由の哲学からはトレーニングデータをなるべくオープンにするというのは正しいとしか言いようがない。
トレーニングデータのソースコード性、透明性と倫理的な側面における検討からは一長一短だと言えるが、オープンソースの根幹にある自由の哲学からはトレーニングデータを全て公開することを要件とする考え方に分があるように思われる。
3.2 法制及び規範面からの検討
各国の法制度ならびにオープンソースの世界における規範面から下記のように両論を整理できるだろう。
オープンソース定義(OSD)との一貫性
思想面でも触れたように、OSD 2条におけるソースコードとは「改変を加えるために好ましい形式」であり、トレーニングデータが最終的なモデルの動作を実際に形成する場合、AIモデルにおける「ソースコード」の法的な概念を満たすと言える。この場合、AIモデルはソースコードであるトレーニングデータの派生物もしくは二次的著作物であると考えられ、オープンソースとして適合するライセンスがデータセットへ適用されていない限り、そのモデルをオープンソースとは呼べない。また、データセットを完全に取得できない場合、派生モデルの作成を妨げられるという考え方もあるだろう。
しかし、実際には機械学習モデルの根幹は確率論的な演算結果である数値データの積み重ねでしかなく、グローバルな知的財産権の考え方では通常このような出力に権利は発生せず、著作権の許諾でしかないライセンスは伝播しないどころか、基本的に何も影響しない。著作権保護されたデータが複製されて出力に残存するようなケースであれば派生と見做せるが、それは極めてレアケースとなるのだろう。日本では情報解析の権利制限規定(著法30条の4等)、シンガポールでは計算機データ解析の権利制限規定が存在するように、AIトレーニングに対して著作物の無許諾の利用が認められている法域もある他、米国でも著作物の変容的利用としてフェアユースに該当する行為であるとの考え方が強い。このようにトレーニングデータの権利がモデルに及ばない状態であるににも関わらず、それを「ソースコード」と見做すのは厳しいように感じられる。また、そもそもAIトレーニングのような情報解析ともデータマイニングとも称される行為は多くの法域で無許諾での著作物の利用が認められているが、そのトレーニングに使用したデータを一般に広く再頒布することは通常は制限されている。ここで、「データを共有する意義」とのミスマッチが生じるだろう。
さらに、フォークの可能性に関しては、一部もしくは多くのデータが欠けていたとしても類似のデータを充足することができるのであれば、フォークは可能と言えるだろう。前節でのフォントでのオープンソース性の判断のアプローチは、まさにこのような元々の材料が存在しないワークフローにおける中間形式からのフォークを認めているように見える。
著作権とプライバシー法
一般的にトレーニングデータには多くの著作物が含まれており、一部の法域ではデータの集合物にデータベース権を付与されることもあり、大規模にキュレーションされたデータセットを何らかの知的財産権で保護された編集物として扱うことは可能である。このデータセットが実際に「ソースコード」である場合、そのデータにオープンソースもしくはそれに類似したライセンスを要求することは、ソフトウェアのソースコードにライセンスを要求することと論理的には一致する。また、それらのトレーニング用のデータセット全体を公開することで、多くの法的な不確実性が解消されるという側面もあるだろう。データの一部が非公開であるなら、そのトレーニングデータを利用したモデルの派生モデルを開発した者はトレーニングデータに関わる契約や許諾、あるいは何らかの法に意図せず違反するリスクを負うことにもなる。
しかし、前項でも書いたように、一般にAIモデルにおけるトレーニングとは確率論的な演算結果の積み重ねであって、現時点において、モデルに対してトレーニングデータの知的財産権の影響は特に何も発生しないというのが多くの法域での考え方であるだろう。データに対する権利がモデルに残存しないのであれば、それが「ソースコード」であるかは説得力が欠けてくる。また、一般に公開されアクセス可能なコンテンツデータの大部分には何らかの使用制限が課せられている可能性が高く、全てのデータをそのまま頒布することは、第三者の権利を侵害するリスクが発生することになる。さらに、多くの法域では、特定の機密情報や個人を特定できる情報の共有はプライバシーデータ保護に関する法(EU GDPR、HIPAA等)によって禁止されている場合が多いだろう。データセット全体の頒布をオープンソースAIにおける条件として要求すると、条件に適合するためにこれらの法律に違反することになってしまうというのは本末転倒であるだろう。
全てのトレーニングデータへ容易にアクセス可能であり、またそれらがオープンソースに類似したライセンス条件で利用できるのであれば、確かに法的な確実性は上がる。また。特定の科学系領域においては、正確な再現性というものが重要であり、そのためにデータの完全性が重要であることは理解できる。しかし、それらのデータに発生している知的財産権が作成されたモデルには残存しないという現在のAIトレーニングに対しての多くの法域での一般的な理解においては、AIモデルがオープンソースと称するための条件としてそれらの完全性を求めるのは中々難しいように感じる。また、一般に共有することが難しいデータというものは様々な分野における機密情報やプライバシーデータ等、多岐に渡るものであり、それらを扱うことでAI開発者を法的リスクに晒すことがないようにするには、生のデータを条件とするのでなく、あくまでデータの来歴等の詳細な情報を求め、派生の可能性を高めるアプローチが向いているように考えられる。よって、「改変を加えるために好ましい形式」を法的に考えると、完全なデータ公開を条件としない方が妥当であり、現実の法や規範に合わせやすいのだろうと考えられる。
3.3. 技術面からの検討
技術面に関しては私は門外漢であるが、一般的な技術解説から検討すると下記のように両論を整理できるだろう。
AIモデル開発と動作分析
AIトレーニングのアルゴリズムはデータから何らかのパターンを学習するものであって、データはウェイトを効果的にプログラミングするとも表現できる。そのため、データはモデルのロジックの一部であるとも言えるのだろう。実際、モデルに何らかの欠陥がある場合、開発者はトレーニングデータの収集やラベル付けの手法を再検討する場合もあるようだ。これはデバッグや改善、あるいはバイアスやエラーの検出といった信頼性確保のための行為のために実施されることもあるのだろう。このような場合は全てのトレーニングデータが自由に入手できることが重要と言える。
一方、実際のモデル開発におけるワークフローにおいては再トレーニングよりも微調整の方が多いという現実がある。多くのAIモデル関連の開発は元のトレーニングデータ全体へのアクセスを必要とせず、ビジネス等におけるドメイン固有のデータに基づいた微調整がほとんどであり、大規模なファウンデーションモデルを最初から再トレーニングし直すという需要はほぼ存在しないだろう。モデルのウェイトとトレーニングのパイプラインの詳細が公開されていれば、それは事実上のフォークとしてモデルの改善を効果的に実行できることになる。AIをオープンソース化することの価値の一つはハイパーパラメータを含めてパイプラインを共有できることでもあり、これによって第三者の開発者が別のデータセット(オープンあるいはプロプライエタリを問わず)で代用して、元のAIモデルのアーキテクチャと方法論のメリットを享受できるのである。
完全な再現の必要性
通常のソフトウェアでは、ソースコードを入手することでビルドを完全に再現できる。だからこそ、ソースコードを入手できることがオープンソースである要件の一つになっているとも言える。それを当てはめればAI領域においても同様に、AIモデルを正確に再現するには完全なデータが必要という主張は理解できるものである。同一のデータがなければ、最終的なモデルには微妙ではあるが重要な点で異なる結果が生じる可能性があると主張する者も多い。
それに対し、非決定論的な演算、ランダムシード、ローカルな開発環境の違いを考慮すると、特に大規模なモデルのトレーニングにおいては完全な再現が事実上不可能であるとも言われている。であれば、ほぼ同等の類似のデータをもってトレーニングを行い、同等のパフォーマンスを達成するのであれば実質的な同等性を実現するという一種の妥協が許容される余地が出てくると考えられる。おそらく、多くのAI/ML開発者や研究者にとっても、「研究」と「改変」の自由というものに完全なビット単位での完全な再現性が含まれるという感覚はあまりないのが実情ではないだろうか?それであれば、詳細なデータドキュメントと完全なトレーニングコードにより、同一の生データを必要とせずに実質的な再現性を実現し、それをもって「研究」と「改変」の自由を確保したという考え方は可能であろう。
データがモデルのロジックの一部であるという考え方も完全なモデルの再現のためには完全なデータが必要であるという考え方も既存のソフトウェア開発においてであれば理解できるものではあるのだろう。ただし、データがモデルの動作を直接的に定義しているわけではなく、モデルの動作がコードのアルゴリズムに依存することは確かであり、さらにデータセットはコードによって処理される単なる入力という側面もあることから、モデルを創造しているソースコードと言えるかは疑わしい部分もある。また、完全に全てのデータとコードが揃っていたとしても完全なモデルの再現が可能であるかも疑わしく、そもそも完全な再現は多くの開発者にとって必要かも疑わしい。オープンソースであるためには「研究」と「改変」の自由が確保される必要があるが、その二つの要件はデータに関する十分に詳細な情報が入手できれば良いという考え方が現実的であるように考えられる。
3.4. 思想、法制、技術の観点からの検討の帰結
AI領域における「改変を加えるために好ましい形式」を思想、法制、技術の各観点で検討したわけだが、思想的には全ての関連するコンポーネントが「自由」であることは我々のコミュニティの哲学としては正義であるかもしれない。
ただし、オープンソースというものは「全ての第三者に対し、著作権法若しくは類似の法上で規定された権利を行使する利用行為への自由を与える法的条件」のことであることを鑑みると、法的な観点における解釈が優先されるだろう。法的観点においては、データに発生している知的財産権が作成されたモデルに残存しないという多くの法域での解釈を鑑みると、やはりデータの完全性は行き過ぎた要件に思えるし、また、プライバシーデータ等の扱いを考慮するとそれらのデータの共有を求める要件というものが現実の社会に適合しないとも考えられる。
さらに、技術的な観点では、モデルを直接的に制御しているのはコードのアルゴリズムであろうし、仮に完全なデータが共有されたとしてもモデルを完全に再現することは困難であり、またその必要性もさほど多くはない。これらを総合して考えると、「改変を加えるために好ましい形式」には完全なデータセットの共有を必須条件とすることは現実的ではなく、それを埋め合わせるために類似のデータを用意できるようにするための情報があれば問題ないという整理ができるのだろう。これにて現実社会における法や規範との整合性が出てくるのだと思う。純粋な思想的なアプローチによるオープン性は完全なトレーニングデータを要求するかもしれないが、トレーニング コード、パラメーター、およびデータ情報を必要とするOSIのアプローチは、オープンソースAIの幅広い採用を促進する実現可能なバランスを実現するだろう。
よって、1節にて提示した Aa – Ab – Bb – Ba の直線の尺度上において、AIシステムがオープンソースであるために必要なデータに関する条件の境界線としては、完全なデータの公開を求めない左側の領域にあるBbに近い所に線引きされると考える。これはOSIが作成したOSAID v1.0におけるデータ情報の要件に近いものである。
4. データ要件に関する将来の展望
オープンソースAIであるための要件に完全なトレーニングデータの共有を要求するかどうかの議論は、完全な再現性と透明性を求める自由の哲学に依拠する考え方と知的財産権やプライバシー等の様々な法的制約と共存しながら現実的なオープン性を求める考え方との間で緊張関係にある。
トレーニングデータの完全な共有への支持者は、データこそがAIの「ソースコード」であり、すべての元の入力がなければモデルの完全な再製や公平性と透明性を実現する監査を実現できないと主張している。一方、OSIが定義したOSAIDのアプローチは、データはモデルのトレーニングに不可欠であるものの、完全なデータセットを共有することは、多くの場合において法的に不可能なケースや実質的に大きな意味がないケースもあるという現実的な考え方に依存している。データセットの詳細で包括的な「データ情報」を要求することでフォークの可能性を維持し、プライバシーや法的制約によって制限されている分野においてもオープンソースAIが実現できるという可能性を残しているとも言えるだろう。
OSAIDは、完全なトレーニングデータの共有がモデルの再現性への最も純粋なルートであることを否定するものではないが、オープンソースAIが現実の世界で成功するためには許容可能な妥協が必要であることを示したものであるのだろう。使用(Use)、研究(Study)、改変(Modify)、共有(Share)の四つの原則を遵守しながら、必要であればトレーニングデータをある程度非公開にできるという現実的な境界線を示しているのである。現時点のOSIのアプローチは、AI領域においてオープンソースの精神を維持しながら、実用的なバランスを取っていると言える。
一方で、「オープンソースAIと称するには完全なトレーニングデータを共有すべきだ」という論点が、今後すぐに決着することはないだろう。AI領域は変化が激しく、進行中の訴訟や各国でのデータプライバシー規制、AI業界における規範の確立など、状況を劇的に変化させる要因が数多く存在するためだ。
例えば、2節で触れているフォントのオープンソース性に関しては、現状ではTTF/OTFがそのままソースコード、つまり「改変を加えるために好ましい形式」としてみなされているが、主要なデザインに関するデータがTTF/OTFの外部に存在するようになった場合には、TTF/OTFだけではソースコードとみなされなくなり、追加のデータの共有がオープンソースであるとみなすための条件となっていくだろう。フォントの例と同様に、AIの領域でも現状のOSAIDよりも実質的なデータの共有が必要になる状況が強まるかもしれないし、それとは逆に、トレーニングデータの完全な標準化が進んだ場合やウェイトの解析だけである程度以上のモデルの機能や性能を正確に把握できるようになった場合にはトレーニングデータの情報すら然程重要ではなくなるかもしれない。どちらの状況になったとしても、結局はその都度に「改変を加えるために好ましい形式」とは何であるかという点を検討し、使用(Use)、研究(Study)、改変(Modify)、共有(Share)の自由を実現できる基準を示すことがOSIには求められるのだろう。
5. 最後に
私はOSAID作成の議論には初期から関わっているが、特に本稿のテーマである完全なトレーニングデータの共有がオープンソースAIであるために必要であるか否かという議論には本当に手こずらされた。非常に難しいテーマであり、立場によって異なる見方になることも分かっているが、両者のバランスを取ろうとする者等を一方的に中傷する者達が出てきたことには本当にうんざりさせられたし、残念でもあった。特に巨大IT企業に属する者からの一方的な攻撃には本当に呆れている。
オープンソースという言葉の歴史は常に自由の哲学と現実的な法と技術のバランスを取ってきたものであり、OSIはAI領域において懸命にその境界線を引くために奔走している。AI領域においては我々のオープンソースコミュニティにとってもまだ未確定な要素も多く、今後も立場の違いにより様々な主張がぶつかり合う可能性はあるだろう。そのような時には、一方的な主張の押しつけではなく、多角的に問題を検討し、現実的な解を見つける努力をしてほしいと願っている。
